数据库扛不住了?这7种扩展策略你必须掌握
为什么需要数据库扩展?
你的应用是不是也遇到过这些问题?
- 查询越来越慢,用户等待时间超过3秒
- 数据量暴涨,单表突破千万级别
- 并发请求激增,数据库CPU常年100%
- 主从延迟严重,数据不一致
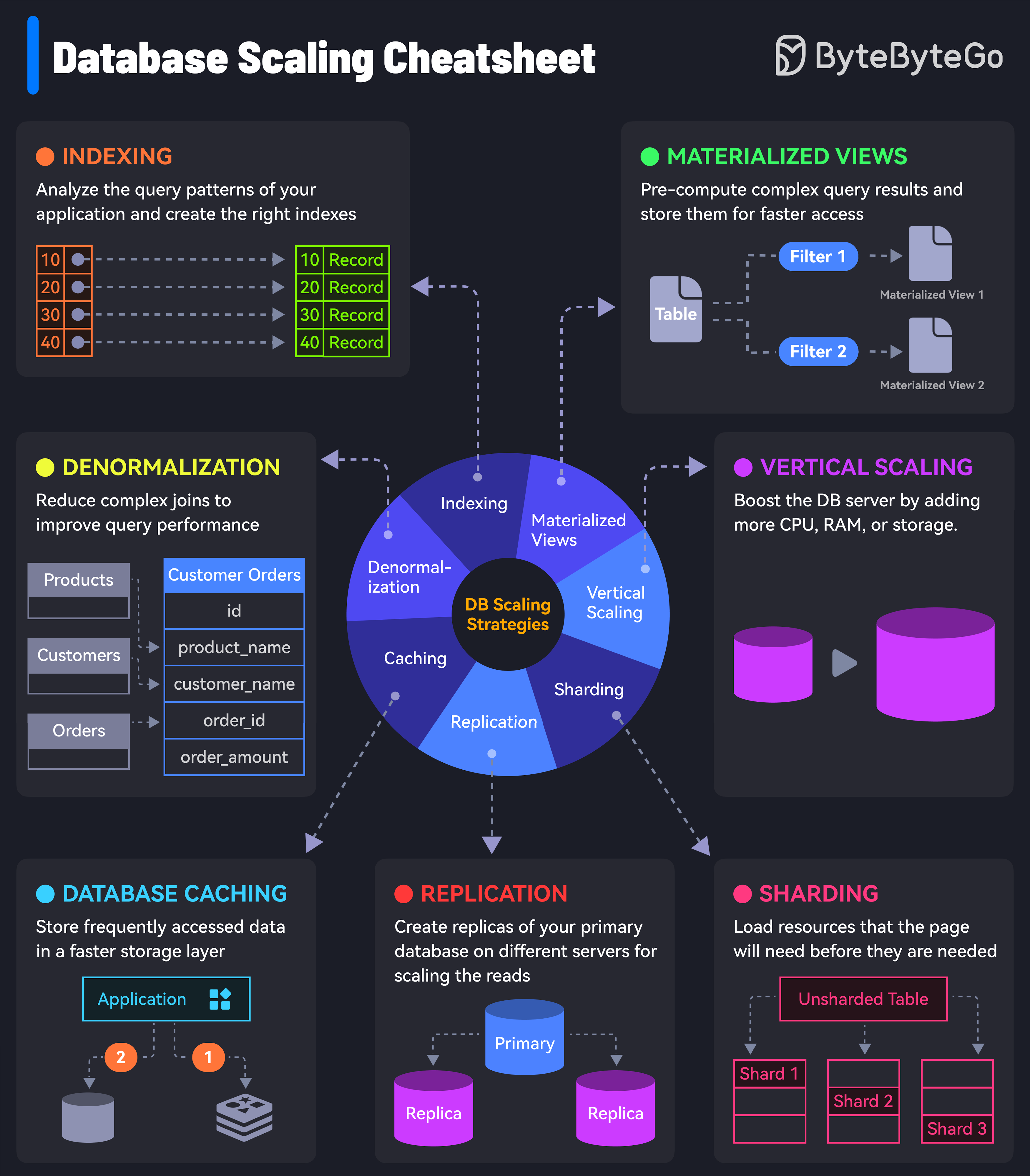
当数据库成为系统瓶颈时,你需要掌握一套完整的扩展策略。今天这张来自ByteByteGo的《Database Scaling Cheatsheet》,系统梳理了7种数据库扩展方案,帮你快速找到适合自己场景的解决方案。
策略一:索引(Indexing)
核心思想: 用空间换时间,通过建立索引加速数据检索。
如何做:
分析应用的查询模式,为高频查询的字段创建合适的索引。比如,你的订单表经常按user_id和create_time查询,就应该建立联合索引。
-- 为订单表创建索引
CREATE INDEX idx_user_time ON orders(user_id, create_time);注意事项:
- 索引不是越多越好,每个索引都会增加写入成本
- 避免在低区分度字段(如性别)建立索引
- 定期检查索引使用情况,删除无用索引
策略二:物化视图(Materialized Views)
核心思想: 预计算复杂查询结果,避免实时计算。
适用场景:
- 复杂的多表关联查询
- 聚合统计报表
- 数据量大但更新不频繁的场景
如何做:
-- 创建物化视图(PostgreSQL语法)
CREATE MATERIALIZED VIEW customer_orders AS
SELECT
c.customer_id,
c.customer_name,
COUNT(o.order_id) as order_count,
SUM(o.order_amount) as total_amount
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_id, c.customer_name;
-- 定期刷新物化视图
REFRESH MATERIALIZED VIEW customer_orders;策略三:反规范化(Denormalization)
核心思想: 牺牲一定的数据冗余,换取查询性能的提升。
适用场景:
- 读多写少的场景
- 查询性能要求极高
- 可接受数据延迟一致
经典案例: 订单详情表将产品名称、客户名称等冗余存储,避免查询时频繁关联多表。
-- 反规范化后的订单表
CREATE TABLE customer_orders (
id BIGINT PRIMARY KEY,
product_name VARCHAR(100), -- 冗余字段
customer_name VARCHAR(100), -- 冗余字段
order_id BIGINT,
order_amount DECIMAL(10,2),
created_at TIMESTAMP
);策略四:垂直扩展(Vertical Scaling)
核心思想: 提升单台服务器的硬件配置。
具体做法:
- 升级CPU核心数
- 增加内存容量
- 使用更快的SSD存储
- 优化网络带宽
优势: 实施简单,无需修改应用代码 劣势: 单机存在性能上限,成本呈指数级增长
何时选择:
- 数据量在百万级别以下
- 预算充足但人力有限
- 快速解决燃眉之急
策略五:数据库缓存(Database Caching)
核心思想: 将热点数据存储在更快的存储层(如Redis)。
典型架构:
应用 → 缓存层(Redis) → 数据库
↓ 命中返回实现示例:
# 伪代码:带缓存的查询
def get_user_info(user_id):
# 先查缓存
cache_key = f"user:{user_id}"
cached_data = redis.get(cache_key)
if cached_data:
return json.loads(cached_data)
# 缓存未命中,查数据库
user_data = db.query("SELECT * FROM users WHERE id = %s", user_id)
# 写入缓存
redis.setex(cache_key, 3600, json.dumps(user_data))
return user_data注意事项:
- 合理设置缓存过期时间
- 注意缓存穿透、雪崩、击穿问题
- 缓存更新策略要一致
策略六:复制(Replication)
核心思想: 创建数据库副本,扩展读取能力。
架构模式:
写入 → 主数据库
↓ 同步
┌──┴──┐
副本1 副本2 → 分担读取请求读写分离示例:
# 伪代码:读写分离
def get_order(order_id):
# 从副本读取
return replica_db.query("SELECT * FROM orders WHERE id = %s", order_id)
def create_order(order_data):
# 写入主库
return primary_db.execute("INSERT INTO orders ...", order_data)注意事项:
- 主从延迟问题,可能读到旧数据
- 副本数量不是越多越好,同步成本会增加
- 需要考虑主库故障的切换方案
策略七:分片(Sharding)
核心思想: 将大表拆分成多个小表,分散到不同服务器。
分片维度:
- 按用户ID分片(用户维度数据隔离)
- 按时间分片(日志、订单数据)
- 按地理位置分片
- 按业务类型分片
示例:
-- 订单表按user_id取模分片
orders_0 -- user_id % 10 = 0
orders_1 -- user_id % 10 = 1
orders_2 -- user_id % 10 = 2
...
orders_9 -- user_id % 10 = 9注意事项:
- 分片键选择至关重要,影响查询效率
- 跨分片查询复杂,需要应用层处理
- 后期扩缩容困难(重新分片成本高)
如何选择合适的扩展策略?
| 场景 | 推荐策略 |
|---|---|
| 查询慢 | 索引、物化视图、反规范化 |
| 读写压力大 | 复制、缓存 |
| 数据量大 | 分片、垂直扩展 |
| 预算有限 | 索引、缓存、反规范化 |
| 快速解决问题 | 垂直扩展、缓存 |
原则:
- 先优化后扩展 - 索引、SQL优化优先
- 从简单到复杂 - 缓存 → 复制 → 分片
- 读写分离 - 优先扩展读取能力
- 分片最后考虑 - 运维成本最高
总结
数据库扩展不是银弹,每种策略都有其适用场景和代价。
- 小规模(百万级):索引优化 + 缓存 + 读写分离
- 中规模(千万级):物化视图 + 反规范化 + 垂直扩展
- 大规模(亿级+):分片 + 复制 + 缓存组合拳
最重要的是,根据业务阶段选择合适的策略,避免过度设计。
如果这篇文章对你有帮助,欢迎点赞、在看、分享!
有任何问题或想法,欢迎在评论区留言讨论~
文章元信息
目标读者: 后端开发工程师、架构师、数据库管理员 难度等级: 中级 预计阅读时间: 8分钟 字数: 约1800字 发布日期建议: 工作日中午或晚上8-10点
SEO关键词:
- 数据库扩展
- 数据库性能优化
- 数据库分片
- 读写分离
- MySQL优化
- Redis缓存
备选标题:
- 数据库性能优化:7种扩展策略全解析
- 从索引到分片:数据库扩展完整指南
- 数据库瓶颈怎么办?一张图教你7种扩展方案
- 程序员必知的7种数据库扩展策略
- 数据库扩展速查表:附架构决策指南
封面图建议: 使用文章中的速查表图片,视觉清晰、信息密度高
喜欢这款工具?关注「善忘技术夹」全媒体
扫描二维码关注微信公众号与小程序,获取更多高品质开源软件推荐与效率工具测试。

