MediaCrawler:一键爬取全网主流平台数据的神器
在数据驱动的时代,如何高效获取各大社交媒体平台的数据成为了开发者和数据分析师的重要需求。今天要为大家介绍一个在GitHub上备受瞩目的开源项目——MediaCrawler,这是一个功能强大的多平台媒体内容爬虫工具。
什么是MediaCrawler?
MediaCrawler是一个支持小红书笔记、抖音视频、快手视频、B站视频、微博帖子、百度贴吧帖子、知乎问答文章等多个平台的内容和评论爬虫工具。该项目在GitHub上霸榜三天,每天以1-2k的速度增长,足见其受欢迎程度。
项目地址: https://github.com/NanmiCoder/MediaCrawler
详细文档: https://nanmicoder.github.io/MediaCrawler/
支持平台
MediaCrawler目前支持以下主流平台:
- • 小红书 - 笔记内容和评论
- • 抖音 - 视频内容和评论
- • 快手 - 视频内容和评论
- • B站 - 视频内容和评论
- • 微博 - 帖子内容和评论
- • 百度贴吧 - 帖子和评论回复
- • 知乎 - 问答文章和评论
环境要求
在开始使用之前,请确保您的环境满足以下要求:
- • Python版本:3.9.6(推荐,其他版本可能需要调整依赖)
- • Node.js版本:16及以上(爬取抖音和知乎时需要)
- • 操作系统:支持Windows、macOS、Linux
安装与配置
1. 创建虚拟环境
首先克隆项目并创建Python虚拟环境:
`# 进入项目根目录 cd MediaCrawler
创建虚拟环境
python -m venv venv
macOS & Linux 激活虚拟环境
source venv/bin/activate
Windows 激活虚拟环境
venv\Scripts\activate`
2. 安装依赖库
安装项目所需的Python依赖包:
pip install -r requirements.txt
3. 安装浏览器驱动
安装playwright浏览器驱动:
playwright install
使用方法
基本使用
项目默认没有开启评论爬取模式,如需评论请在config/base_config.py中的ENABLE_GET_COMMENTS变量修改。
关键词搜索爬取:
# 从配置文件中读取关键词搜索相关的帖子并爬取帖子信息与评论 python main.py --platform xhs --lt qrcode --type search
指定帖子ID爬取:
# 从配置文件中读取指定的帖子ID列表获取指定帖子的信息与评论信息 python main.py --platform xhs --lt qrcode --type detail
查看更多选项:
python main.py --help
登录方式
使用--lt qrcode参数时,程序会打开对应APP的二维码登录页面,您需要使用手机APP扫码登录。
数据保存
MediaCrawler支持多种数据保存方式:
-
- MySQL数据库:
- • 需要提前创建数据库
- • 首次使用需执行
python db.py初始化数据库表结构
-
- CSV格式:数据保存在
data/目录下的CSV文件中
- CSV格式:数据保存在
-
- JSON格式:数据保存在
data/目录下的JSON文件中
- JSON格式:数据保存在
配置文件说明
在config/base_config.py文件中,您可以配置各种功能选项:
- • ENABLE_GET_COMMENTS:是否开启评论爬取
- • 其他配置选项都有详细的中文注释说明
使用时修改base_config.py文件即可,比如说我抓取小红书内容,只需要修改需要抓取的关键字即可
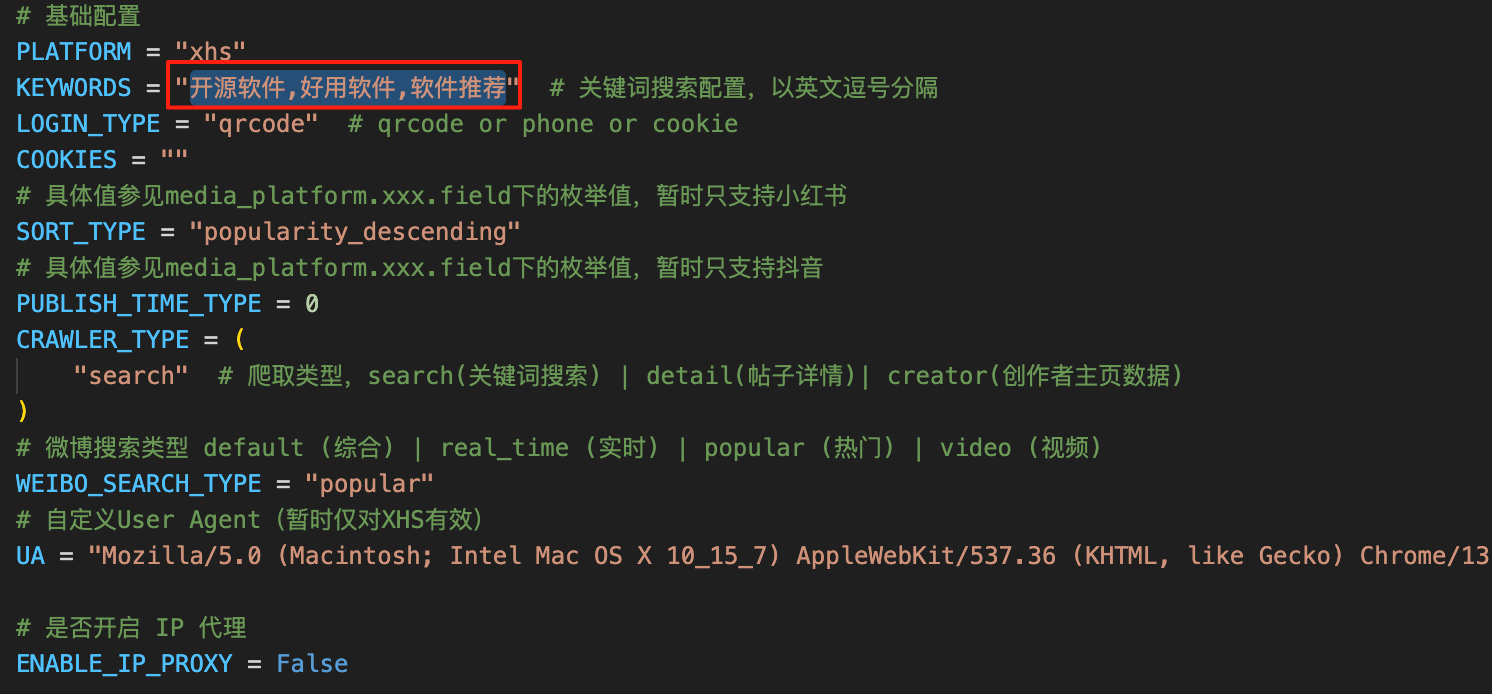
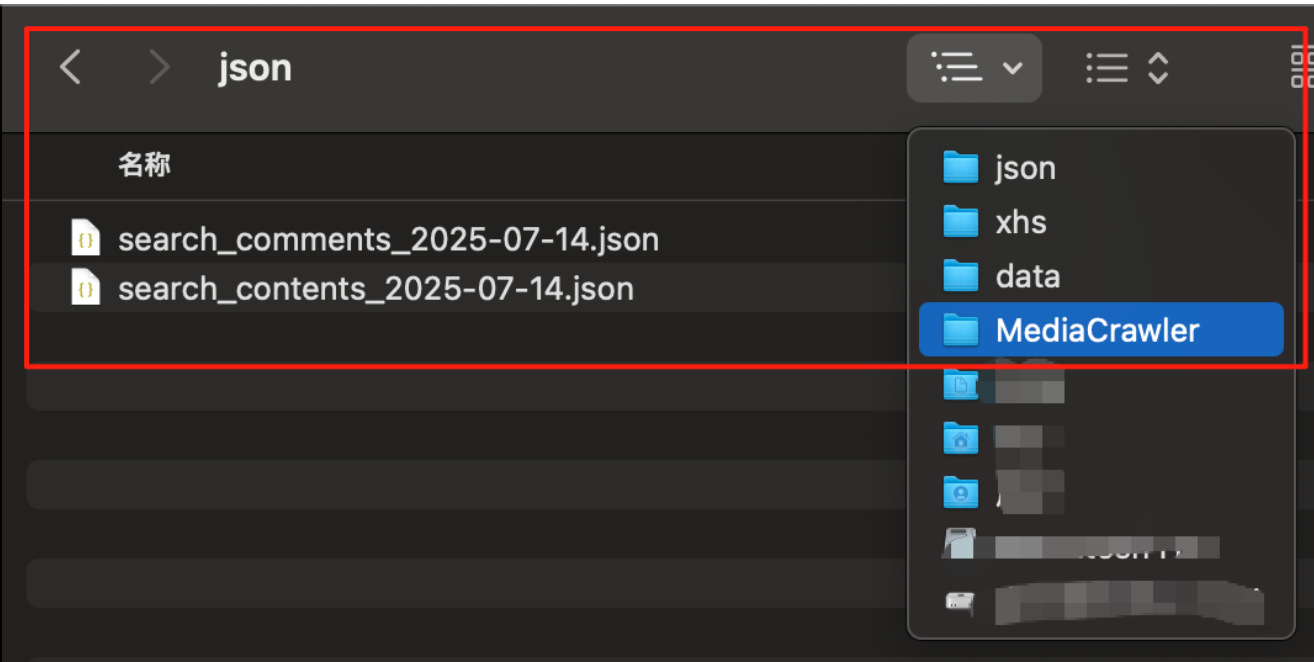
抓取的数据在我没有配置数据库的情况下, 默认json格式放入data目录下,一个是评论,一个是帖子内容
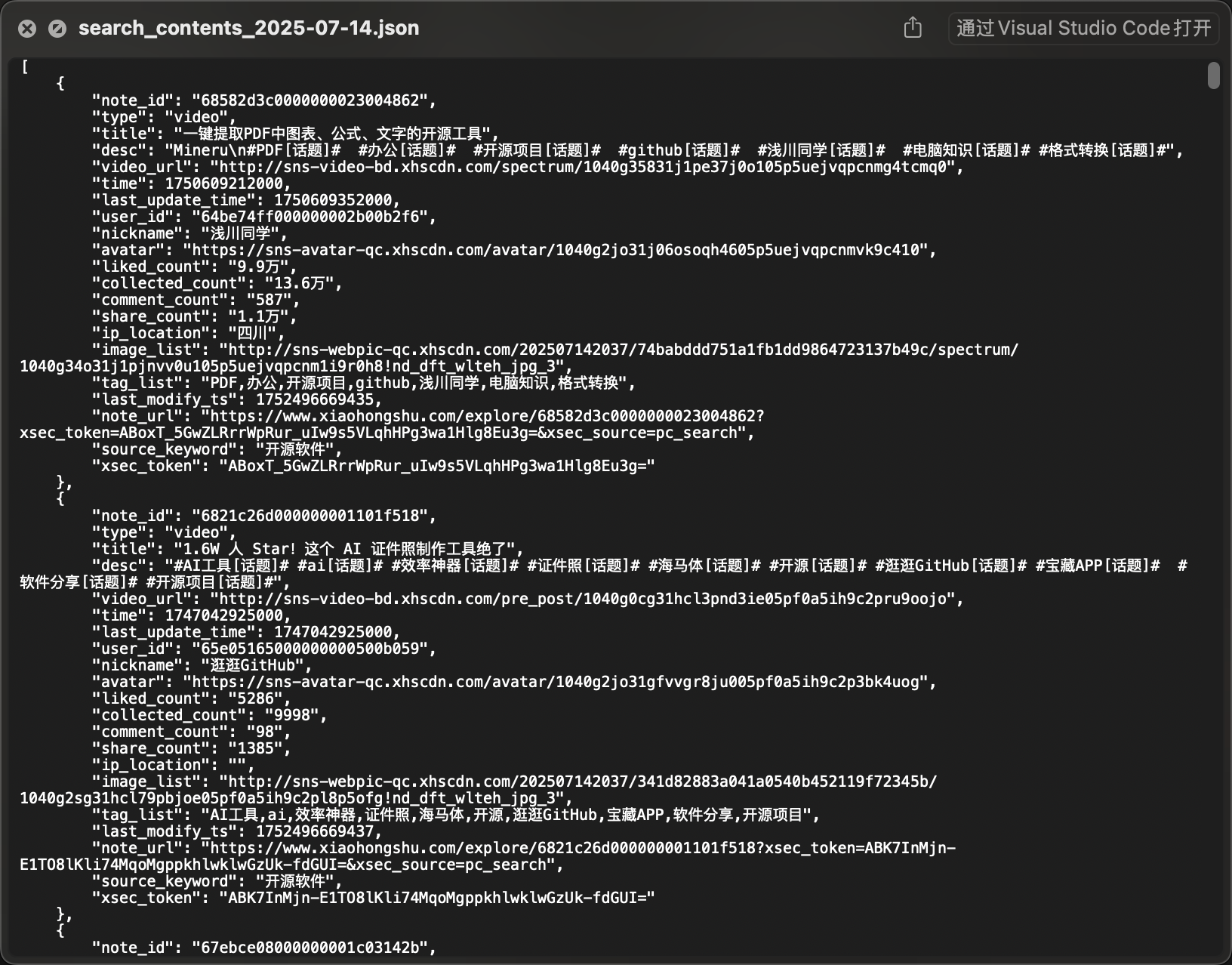
帖子内容
json数据格式清晰, 方便后续入库或者解析
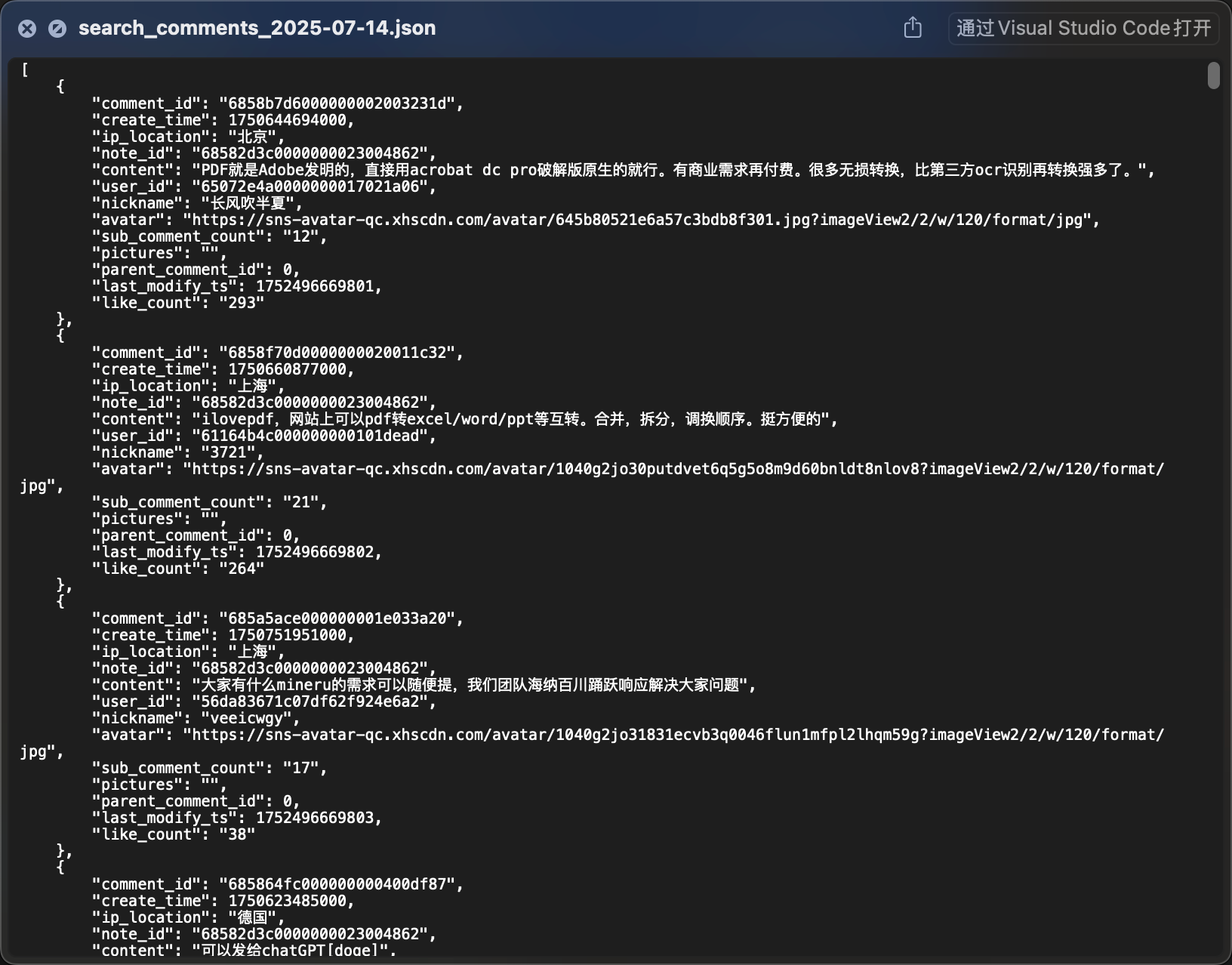
评论
使用场景
MediaCrawler适用于以下场景:
-
- 数据分析研究:收集社交媒体数据进行趋势分析
-
- 内容监控:监控特定关键词的讨论情况
-
- 竞品分析:分析竞争对手的内容策略
-
- 学术研究:收集研究所需的社交媒体数据
-
- 市场调研:了解用户对产品或服务的反馈
重要提醒
免责声明
本项目的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。
合规使用
- • 请遵守各平台的服务条款
- • 不要进行大规模爬取
- • 合理控制爬取频率
- • 仅用于学习和研究目的
项目亮点
-
- 多平台支持:一个工具覆盖主流社交媒体平台
-
- 易于使用:简单的命令行操作
-
- 灵活配置:支持多种数据保存格式
-
- 活跃维护:项目持续更新和优化
-
- 开源免费:完全开源,社区驱动
结语
MediaCrawler作为一个功能强大的多平台爬虫工具,为数据获取提供了极大的便利。无论您是数据分析师、研究人员还是开发者,这个工具都能帮助您高效地收集所需的社交媒体数据。
记住,在使用任何爬虫工具时,都要遵守相关法律法规和平台规则,以学习和研究为目的进行合理使用。
再次提醒项目地址:
- • GitHub:https://github.com/NanmiCoder/MediaCrawler
- • 使用文档:https://nanmicoder.github.io/MediaCrawler/
希望这个工具能为您的数据获取工作带来帮助!
本文由善忘技术夹整理发布,更多技术干货请关注我们的公众号。
喜欢这款工具?关注「善忘技术夹」全媒体
扫描二维码关注微信公众号与小程序,获取更多高品质开源软件推荐与效率工具测试。

