上传GB级文件到对象存储,90%的开发者都踩过这个坑!
- 前言
- 面试加分项:为什么要用分片上传?
- 为什么分片上传能解决问题?
- 分片上传的完整流程
- 第一步:初始化上传
- 第二步:上传分片
- 第三步:合并分片
- 生产级代码实现
- 最佳实践建议
- 1. 分片大小选择
- 2. 并发控制
- 3. 错误处理与重试机制
- 4. 清理未完成的上传
- 通用性验证
- 总结:如何回答面试中的大文件上传问题?
前言
“如果用户要上传一个2GB的视频文件,你会怎么设计上传方案?”
这是我在面试中经常问的问题,也是很多后端开发者在实际工作中会遇到的真实场景。
当你面对几百MB甚至几个GB的大文件上传需求时,如果直接用简单的 putObject 方法上传,大概率会遇到这些问题:
❌ 网络一抖,上传失败,得重新传
❌ 文件太大,内存直接爆掉
❌ 上传进度看不到,用户体验极差
❌ 无法暂停,只能傻等上传完成
今天我们就来聊聊,如何优雅地解决大文件上传问题 —— 分片上传(Multipart Upload)。这不仅是生产环境的最佳实践,也是面试中的高频考点。
面试加分项:为什么要用分片上传?
在回答面试问题时,除了说"使用分片上传",更要能解释清楚为什么。
分片上传的核心思想很简单:把大文件切成多个小片段,分别上传,最后在服务端合并。
为什么分片上传能解决问题?
✅ 断点续传:某个分片失败,只需重传该分片
✅ 并行上传:多个分片同时传,速度倍增
✅ 内存友好:每次只处理一个小分片
✅ 进度可见:根据分片进度计算总进度
✅ 网络容错:弱网环境下成功率更高
分片上传的完整流程
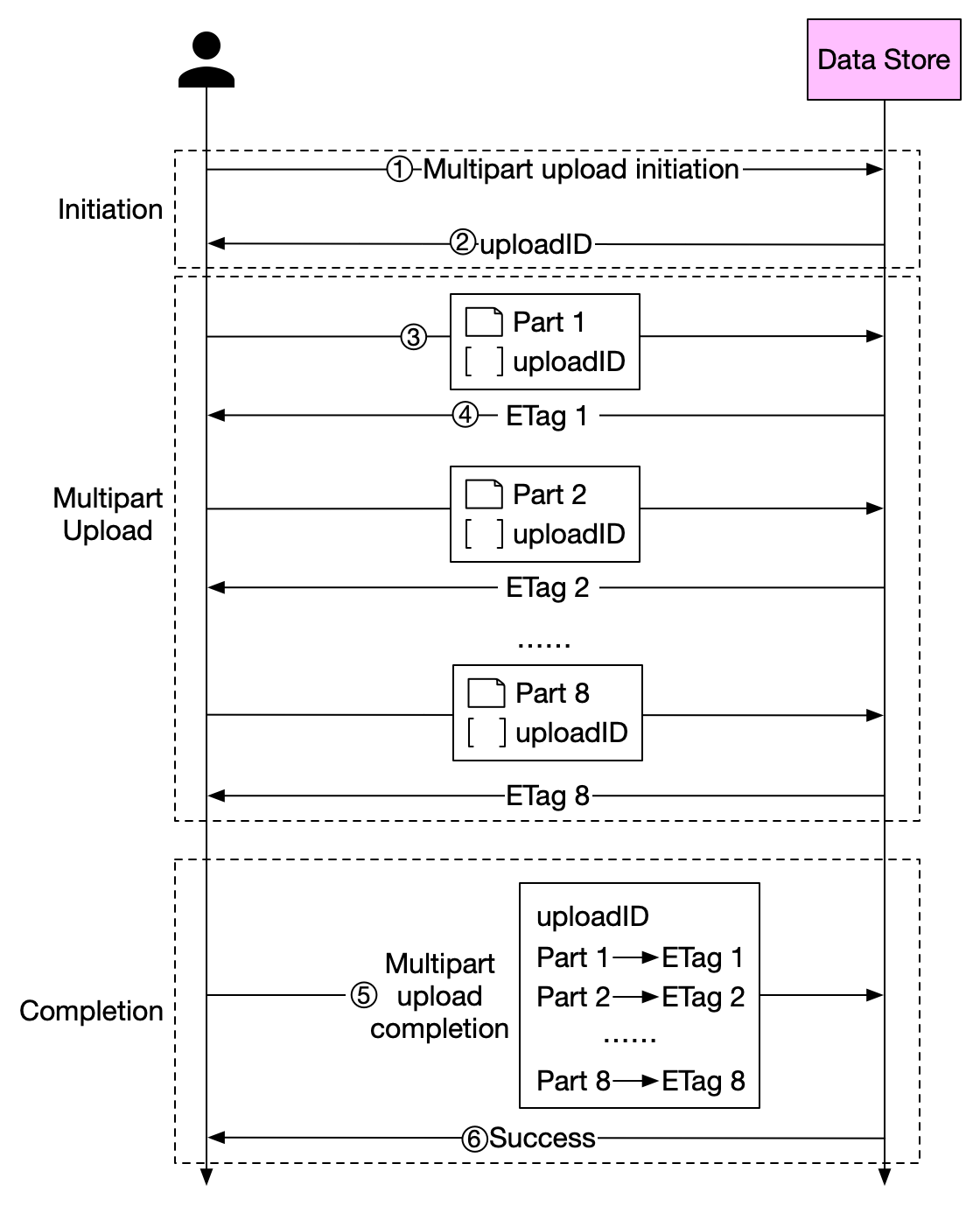
根据S3协议规范,分片上传分为三个步骤:
第一步:初始化上传
const uploadId = await s3.createMultipartUpload({
Bucket: 'my-bucket',
Key: 'large-file.zip'
}).uploadId;
这一步会告诉对象存储:“我要开始上传一个分片文件了”,并返回一个 uploadId,后续所有操作都要带着这个ID。
第二步:上传分片
const partSize = 5 * 1024 * 1024; // 5MB每片
const parts = [];
for (let i = 0; i < totalParts; i++) {
const start = i * partSize;
const end = Math.min(start + partSize, fileSize);
const chunk = file.slice(start, end);
const result = await s3.uploadPart({
Bucket: 'my-bucket',
Key: 'large-file.zip',
UploadId: uploadId,
PartNumber: i + 1,
Body: chunk
});
parts.push({
PartNumber: i + 1,
ETag: result.ETag
});
}
注意两个关键点:
- PartNumber 从1开始递增
- 必须保存每个分片的ETag,最后合并时要用
第三步:合并分片
await s3.completeMultipartUpload({
Bucket: 'my-bucket',
Key: 'large-file.zip',
UploadId: uploadId,
MultipartUpload: {
Parts: parts
}
});
对象存储会按照 PartNumber 顺序,把所有分片合并成完整文件。
生产级代码实现
这里给你一个完整的TypeScript实现,可以直接用于项目:
import * as AWS from 'aws-sdk';
class S3MultipartUploader {
private s3: AWS.S3;
private partSize = 5 * 1024 * 1024; // 5MB
constructor() {
this.s3 = new AWS.S3({
endpoint: 'https://s3.amazonaws.com', // 或OSS、MinIO的endpoint
accessKeyId: process.env.AWS_ACCESS_KEY_ID,
secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY
});
}
async uploadFile(
bucket: string,
key: string,
file: Buffer,
onProgress?: (progress: number) => void
): Promise<string> {
// 1. 初始化上传
const { UploadId } = await this.s3.createMultipartUpload({
Bucket: bucket,
Key: key
}).promise();
// 2. 计算分片数量
const totalParts = Math.ceil(file.length / this.partSize);
const parts: AWS.S3.Part[] = [];
// 3. 并发上传分片
const uploadPromises = [];
const concurrency = 3; // 并发数
for (let i = 0; i < totalParts; i++) {
const partNumber = i + 1;
const start = i * this.partSize;
const end = Math.min(start + this.partSize, file.length);
const chunk = file.slice(start, end);
const uploadPromise = this.s3.uploadPart({
Bucket: bucket,
Key: key,
UploadId,
PartNumber: partNumber,
Body: chunk
}).promise()
.then(result => {
parts.push({
PartNumber: partNumber,
ETag: result.ETag!
});
// 上报进度
if (onProgress) {
const progress = (parts.length / totalParts) * 100;
onProgress(progress);
}
});
uploadPromises.push(uploadPromise);
// 控制并发数
if (uploadPromises.length >= concurrency || i === totalParts - 1) {
await Promise.all(uploadPromises);
uploadPromises.length = 0;
}
}
// 4. 合并分片
await this.s3.completeMultipartUpload({
Bucket: bucket,
Key: key,
UploadId,
MultipartUpload: { Parts: parts.sort((a, b) => a.PartNumber - b.PartNumber) }
}).promise();
return `s3://${bucket}/${key}`;
}
// 取消上传
async abortUpload(bucket: string, key: string, uploadId: string): Promise<void> {
await this.s3.abortMultipartUpload({
Bucket: bucket,
Key: key,
UploadId: uploadId
}).promise();
}
}
// 使用示例
const uploader = new S3MultipartUploader();
uploader.uploadFile(
'my-bucket',
'large-video.mp4',
fileBuffer,
(progress) => console.log(`上传进度: ${progress.toFixed(2)}%`)
);
最佳实践建议
💡 面试提示:在面试中,除了说出技术方案,还要能权衡各种参数的利弊,这会让面试官眼前一亮。
1. 分片大小选择
- 推荐 5-10MB:太小会增加请求次数,太大会降低并发优势
- S3允许 1MB-5GB 的分片大小
- 最多支持 10000 个分片
面试加分回答:
“我会根据文件大小和网络情况动态调整。对于100MB的文件,5MB分片足够;对于10GB的文件,我会设置10MB分片以减少分片数量。”
2. 并发控制
- 推荐并发数 3-5:避免带宽打满导致超时
- 可根据网络情况动态调整
面试加分回答:
“我会实现一个动态并发控制器,根据当前网络状况和分片大小自动调整并发数,既能充分利用带宽,又不会导致超时。”
3. 错误处理与重试机制
// 添加重试机制
async uploadPartWithRetry(params, maxRetries = 3) {
for (let i = 0; i < maxRetries; i++) {
try {
return await this.s3.uploadPart(params).promise();
} catch (error) {
if (i === maxRetries - 1) throw error;
await new Promise(resolve => setTimeout(resolve, 1000 * (i + 1)));
}
}
}
4. 清理未完成的上传
// 列出所有未完成的分片上传
const incompleteUploads = await s3.listMultipartUploads({
Bucket: 'my-bucket',
'Max-Uploads': 1000
}).promise();
// 清理超过7天的未完成上传
for (const upload of incompleteUploads.Uploads || []) {
const initiatedDate = new Date(upload.Initiated);
const daysSinceInitiated = (Date.now() - initiatedDate.getTime()) / (1000 * 60 * 60 * 24);
if (daysSinceInitiated > 7) {
await s3.abortMultipartUpload({
Bucket: upload.Bucket,
Key: upload.Key,
UploadId: upload.UploadId
}).promise();
}
}
通用性验证
这套方案不仅适用于 AWS S3,所有兼容 S3 协议的对象存储都支持:
✅ 阿里云 OSS - 完全支持分片上传
✅ 腾讯云 COS - API完全兼容
✅ MinIO - 开源对象存储,完全兼容
✅ 华为云 OBS - 支持 S3 协议
✅ 自建对象存储 - 只要是S3协议即可
只需要修改 endpoint 和认证信息即可。
总结:如何回答面试中的大文件上传问题?
如果面试官问你:“如何设计一个大文件上传系统?”
标准回答框架:
- 问题分析(15秒)
- 大文件上传的痛点:网络不稳定、内存占用、无法断点续传
- 核心方案(30秒)
- 使用分片上传(Multipart Upload)
- 初始化 → 分片上传 → 合并
- 技术亮点(1分钟)
- 实现断点续传(保存 uploadId 和 part 信息)
- 并发控制提升速度(3-5个并发)
- 重试机制保证可靠性(指数退避)
- 进度反馈优化体验
- 工程思维(30秒)
- 清理未完成上传,避免浪费存储空间
- 分片大小根据网络环境动态调整
- 支持多种对象存储(S3/OSS/MinIO)
大文件上传的核心要点:
- 永远不要直接上传大文件 - 使用分片上传
- 合理设置分片大小 - 5-10MB 是黄金区间
- 控制并发数 - 避免带宽打满
- 实现断点续传 - 提升用户体验
- 记得清理未完成的上传 - 避免存储空间浪费
记住:分片上传不是可有可无的优化,而是处理大文件的标准方案。
🎯 思考题: 如果用户在上传到一半时关闭了浏览器,再次打开时如何实现断点续传?(提示:需要保存 uploadId 和已上传的 part 信息)
📚 延伸阅读:

评论
发表评论
|
|
|