数据库引擎背后的8种核心数据结构
- 一、为什么没有"银弹"数据结构?
- 二、8种核心数据结构全景图
- 三、内存索引:速度至上
- 1. Skiplist(跳表)
- 2. Hash Index(哈希索引)
- 四、磁盘索引:持久化的艺术
- 3. SSTable(Sorted String Table)
- 4. LSM Tree(Log-Structured Merge Tree)
- 5. B-tree(B树)
- 五、专用索引:为特定场景而生
- 6. Inverted Index(倒排索引)
- 7. Suffix Tree(后缀树)
- 8. R-tree
- 六、如何选择适合你的数据结构?
- 七、总结
你的数据库选择什么索引,本质上是在问:你的应用是读多还是写多?
当我们谈论数据库性能优化时,往往会不自觉地想到"加个索引"这个万能答案。但你有没有想过:索引本身也需要数据结构来支撑?而选择什么样的数据结构,直接决定了你的数据库在高并发场景下的表现。
今天,我们来深入探讨支撑现代数据库系统的8种核心数据结构。
一、为什么没有"银弹"数据结构?
答案取决于你的使用场景:
- 数据存储位置:内存还是磁盘?
- 数据格式:数字、字符串、地理坐标…
- 读写模式:读多写少?写多读少?
这些因素共同决定了你应该选择什么样的索引格式。
二、8种核心数据结构全景图
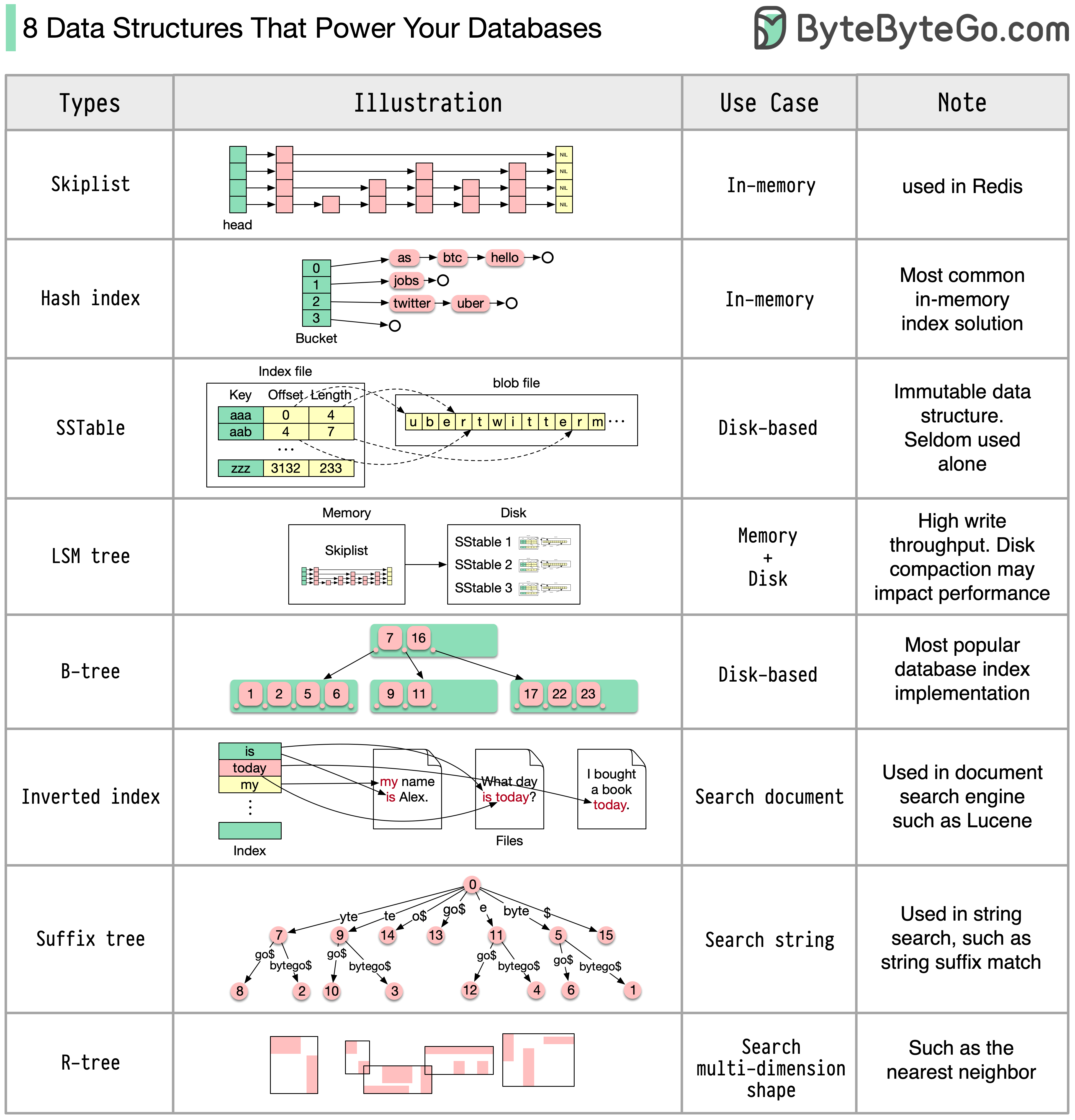
三、内存索引:速度至上
1. Skiplist(跳表)
使用场景:内存索引
典型案例:Redis ZSET
跳表是什么?想象一下,你在地铁里找出口。如果只有一条通道(链表),你需要从头走到尾。但如果有"捷径"(多层索引),你就可以"跳"过很多节点,快速找到目标。
跳表通过多层链表结构,将查找时间从 O(n) 降低到 O(log n),同时保持插入删除的简单性。
为什么Redis选择跳表而不是平衡二叉树?
- 实现简单,不需要复杂的旋转操作
- 范围查询更高效(天然的有序链表)
- 内存访问模式更友好
2. Hash Index(哈希索引)
使用场景:内存索引
特点:最常见的内存索引实现
哈希索引 = 哈希表 = 最快的精确查询
O(1) 的查找效率让它成为精确匹配的首选。但代价是什么?
- 不支持范围查询:你不能查找"所有 age > 18 的用户"
- 哈希冲突:需要处理碰撞,影响性能
- 无序性:无法利用数据的局部性原理
四、磁盘索引:持久化的艺术
3. SSTable(Sorted String Table)
使用场景:磁盘索引
特点:不可变的数据结构,很少单独使用
SSTable 的核心思想:数据一旦写入,永不修改。
这听起来很极端,但带来了巨大好处:
- 写操作极快:顺序写入磁盘,无需随机 I/O
- 读操作简单:数据有序,可以用二分查找
- 并发安全:不可变意味着没有锁竞争
但它也有致命弱点:无法高效更新。这就引出了下一个结构…
4. LSM Tree(Log-Structured Merge Tree)
使用场景:内存 + 磁盘
特点:高写入吞吐量
LSM Tree = Skiplist(内存) + SSTable(磁盘)
工作原理:
1. 写入:数据先写入内存的 Skiplist(MemTable)
2. 刷新:内存满了,排序后写入磁盘成为 SSTable
3. 合并:后台定期合并多个 SSTable,减少文件数量
优势:将随机写转化为顺序写,写入性能极佳
劣势:读取可能需要查询多个 SSTable,磁盘压缩可能影响性能
HBase、Cassandra、RocksDB 都在使用 LSM Tree。
5. B-tree(B树)
使用场景:磁盘索引
特点:最流行的数据库索引实现
MySQL 的 InnoDB、PostgreSQL、MongoDB…几乎所有关系型数据库都在用 B-tree(或其变种 B+ tree)。
为什么 B-tree 适合磁盘?
磁盘 I/O 是昂贵的。B-tree 通过一个关键设计优化了这一点:每个节点可以存储多个 key。
这意味着:
- 树的高度更低:一次磁盘 I/O 能读取更多数据
- 读写性能稳定:查询时间稳定在 O(log n)
- 范围查询友好:B+ tree 的叶子节点形成链表
LSM Tree vs B-tree:
- 写密集型:选 LSM(时序数据、日志、消息队列)
- 读密集型:选 B-tree(传统 OLTP 业务)
五、专用索引:为特定场景而生
6. Inverted Index(倒排索引)
使用场景:文档搜索
典型案例:Lucene、Elasticsearch
你在 Google 搜索"数据库原理"时,它是怎么快速找到包含这两个词的文档的?
倒排索引的核心思想:从"文档→词语"翻转为"词语→文档"。
文档1: "数据库原理很有趣"
文档2: "我喜欢学习数据库"
倒排索引:
"数据库" → [文档1, 文档2]
"原理" → [文档1]
"很有趣" → [文档1]
这使得全文搜索变得极其高效。
7. Suffix Tree(后缀树)
使用场景:字符串模式搜索
应用:字符串后缀匹配
想象一下,你需要在 10GB 的文本中找出所有包含"banana"的子串位置。
后缀树将字符串的所有后缀组织成一棵压缩的字典树,使得:
- 子串查找:O(m) 时间复杂度(m 为模式长度)
- 最长重复子串
- 最长公共子串
基因序列分析、文本压缩、生物信息学都在使用它。
8. R-tree
使用场景:多维空间搜索
应用:最近邻搜索、地理信息系统
“查找距离我 5km 内的所有咖啡店”
B-tree 只能处理一维数据(数字、字符串),但地理位置是二维的(经度、纬度)。
R-tree 将空间数据组织成层次化的边界矩形:
- 每个节点用一个矩形包围其子节点
- 查询时只需判断矩形是否与搜索区域相交
PostGIS、MongoDB 的 2d 索引都在使用 R-tree 的变种。
六、如何选择适合你的数据结构?
| 场景 | 推荐数据结构 | 典型代表 |
|---|---|---|
| 精确查询(内存) | Hash Index | Redis Hash |
| 有序集合(内存) | Skiplist | Redis ZSET |
| 写密集型 | LSM Tree | HBase, RocksDB |
| 读密集型 | B-tree | MySQL, PostgreSQL |
| 全文搜索 | Inverted Index | Elasticsearch |
| 字符串匹配 | Suffix Tree | 基因分析工具 |
| 地理位置查询 | R-tree | PostGIS |
七、总结
数据库索引的世界里,没有"最好"的数据结构,只有"最适合"的。
理解这些底层结构,能帮助你:
1. 选择合适的数据库:为什么用 Elasticsearch 而不是 MySQL 做全文搜索?
2. 优化查询性能:为什么 GeoHash 查询在 MySQL 中很慢?
3. 设计更好的系统:时序数据为什么要用 LSM 结构?
下次当你遇到性能瓶颈时,不妨问问自己:我选对数据结构了吗?

评论
发表评论
|
|
|